Introduction to Hash Table
— data-structures, algorithms — 1 min read
Hash tables are very efficient. Let’s say that we want to look up a specific person in an array: we would have to walk through every item to look for that person! The space complexity would be O(n), as space depends on the size of the array.
To look things up way more efficiently, you can use hash tables! Hash tables are made up of two parts: an object with the table where the data will be stored, and a hash function (or mapping function). This function creates a mapping by assigning the input data to a very specific index within the array! This function takes a key, and always returns the same index for the same key! If we would run the same key through the function twice, it gives us the same index.
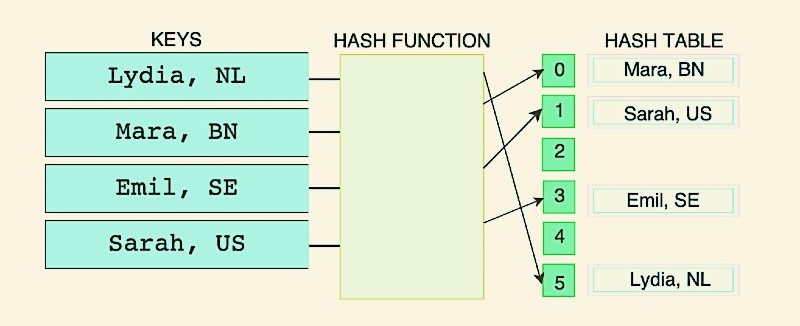
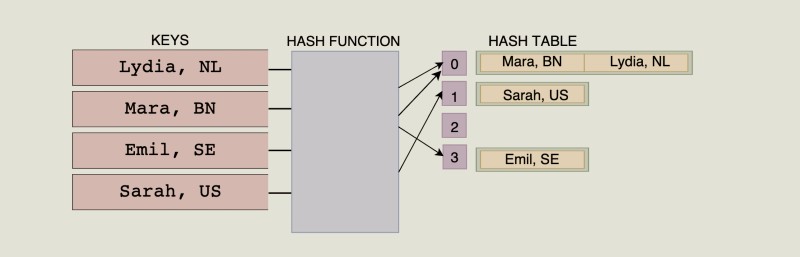
As the hash function always gives the same hash for every key, we can easily look up key/value pairs. Instead of having to map over an entire object, we just pass the key we want to the hash function, which then returns the index where this key/value pair is stored!
However, sometimes the hash function returns the same index for different keys. This is called collision.